
前言#
创新实践课程着实是一门大水课,但是沈力老师着实是一位很有激情的老师。
虽然这是一门水课,但是我记起来一句话,记得是大一在华工转专业群的一位学长口中听到的:
水课的意义就是让你知道有这么一个东西。
那好,我现在正缺少深度学习的密集实践。借助这门课的机会,尝试在实践中让枯燥漂浮的理论变得生动接地气起来。
AlexNet 如何让 NN 再次伟大#
人工特征统治了世界太久,却没有人发掘 GPU 里面日益增长的算力的价值。AlexNet 用扎实的工程功底针对「让一个超大网络能被训练」这个问题做了很多创新的模型设计,并运用了很多训练技巧。
AlexNet 证明了“深度 + 数据 + 计算”,后续工作只是不断逼近这个范式的极限。
模型总览#
在最初的 AlexNet 论文1里面,网络结构是基于 LeNet 并妥协了当时尚未成熟的 DNN 软硬件件环境(比如卡均显存很小,只有原始的 CUDA C++ 加速库)而设计的。AlexNet 的网络结构如下图所示2:
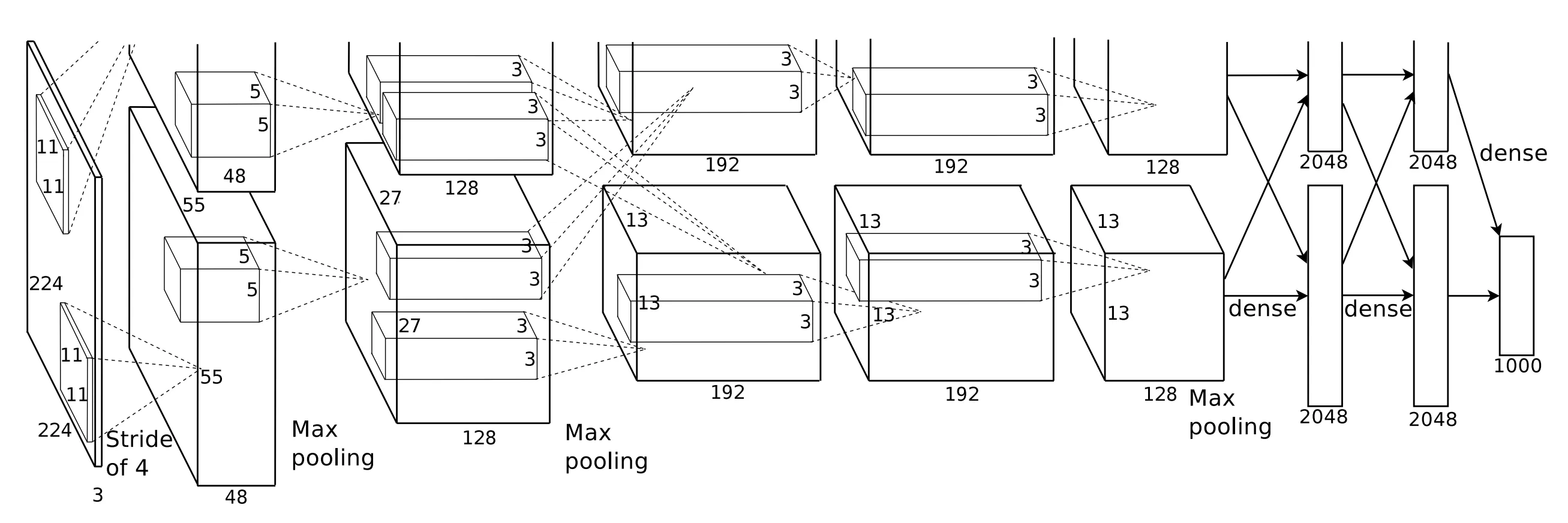
由于历史时代限制,AlexNet 的网络结构设计中包含了很多妥协/在今天看来多余、不必要的设计,比如:
- 大卷积 +
- LRN(局部响应归一化)
- 分组卷积(因为单卡放不下)
- 强依赖 FC()
- 手写 CUDA 实现
在不需要为软硬件做出大量妥协的今天,AlexNet 被深度学习界的前辈们还原成了一个「干净的 CNN baseline」:

也就是经典的: 两层
Conv → ReLU → Pool构成了特征提取器,三层FC → ReLU构成了分类器。
Input
→ Conv1 → ReLU → MaxPool
→ Conv2 → ReLU → MaxPool
→ Conv3 → ReLU
→ Conv4 → ReLU
→ Conv5 → ReLU → MaxPool
→ Flatten
→ FC → ReLU → Dropout
→ FC → ReLU → Dropout
→ FC → Softmax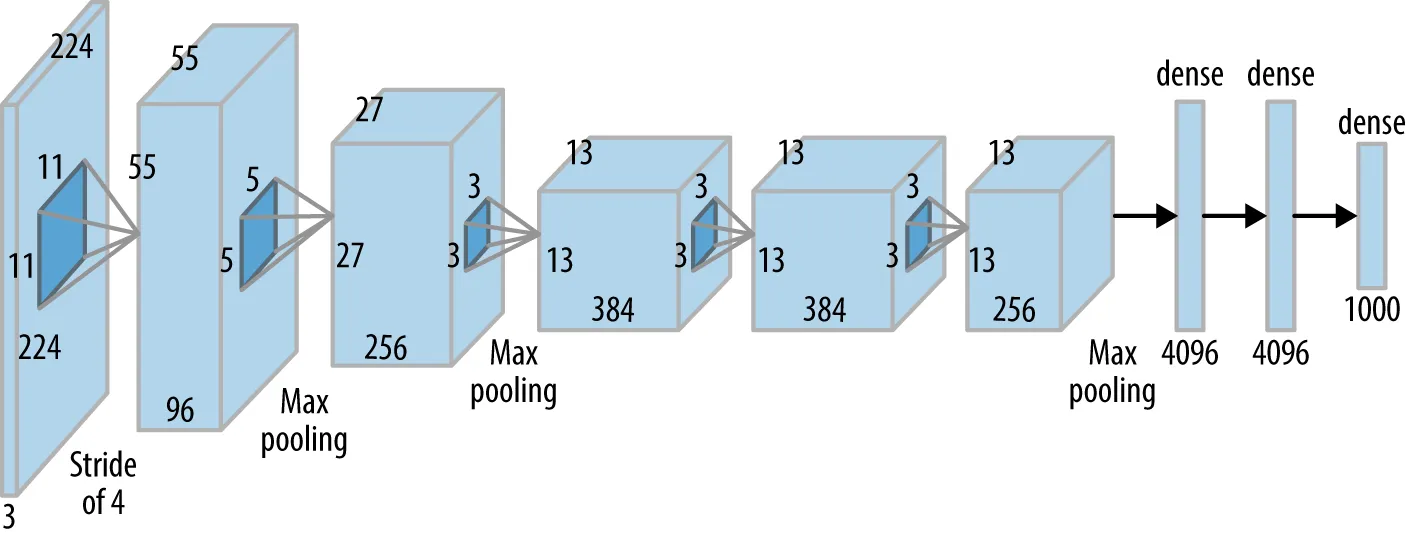
特征提取器#
在输入进入 pipeline 的前期,经过了两层 Conv → ReLU → Pool 结构,其中:
Conv的作用是提取局部特征,保留位置信息。ReLU的作用是引入非线性,具有非线性激活函数的网络可以逼近任意连续函数3。Pool的作用是降低特征图的分辨率(下采样),模糊位置信息,减少计算量,也就是信息压缩。
分类器#
丰富的多频道特征在 pipeline 的中期(flatten)被压缩成了一个一维的特征向量,进入了后续的三层 FC → ReLU 结构,开始逐步降维。
MLP 理论上有能够学习任何函数的能力,在这里三层恰好是一个平衡表现能力和计算效率(收敛难度)的选择。
这里在 FC 层后面还加了 Dropout 正则化,来防止过拟合。(后面会介绍 Dropout 的原理和作用)
pipeline 可视化#
为进一步观察最优模型的中间表征与判别区域,选取验证集中的一张 daisy 样本,对最优权重 augment_weight_decay 进行特征图与 Grad-CAM 可视化。该样例最终预测类别为 daisy,预测置信度为 1.0000。

上图展示了输入图像以及 5 个卷积层中激活最强的部分通道。该可视化反映了 AlexNet 从浅层局部纹理到深层高阶语义表征的逐级抽象过程,也说明最优模型在该样本上能够形成较稳定的层级特征响应。
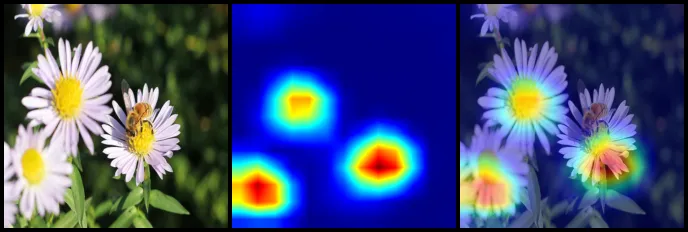
Grad-CAM 作用于最后一层卷积层 features.10,用于展示分类决策对应的空间响应区域。结合该样例被正确分类为 daisy 的结果,可以看出该可视化为模型判别依据提供了直观解释,有助于从单样本层面补充对模型可解释性的观察。
ReLU:让模型更快收敛#
当时业界普遍使用的激活函数是 和 4,AlexNet 首次在深度卷积网络中使用了 ReLU 激活函数5,并且证明了它能够让模型更快地收敛。
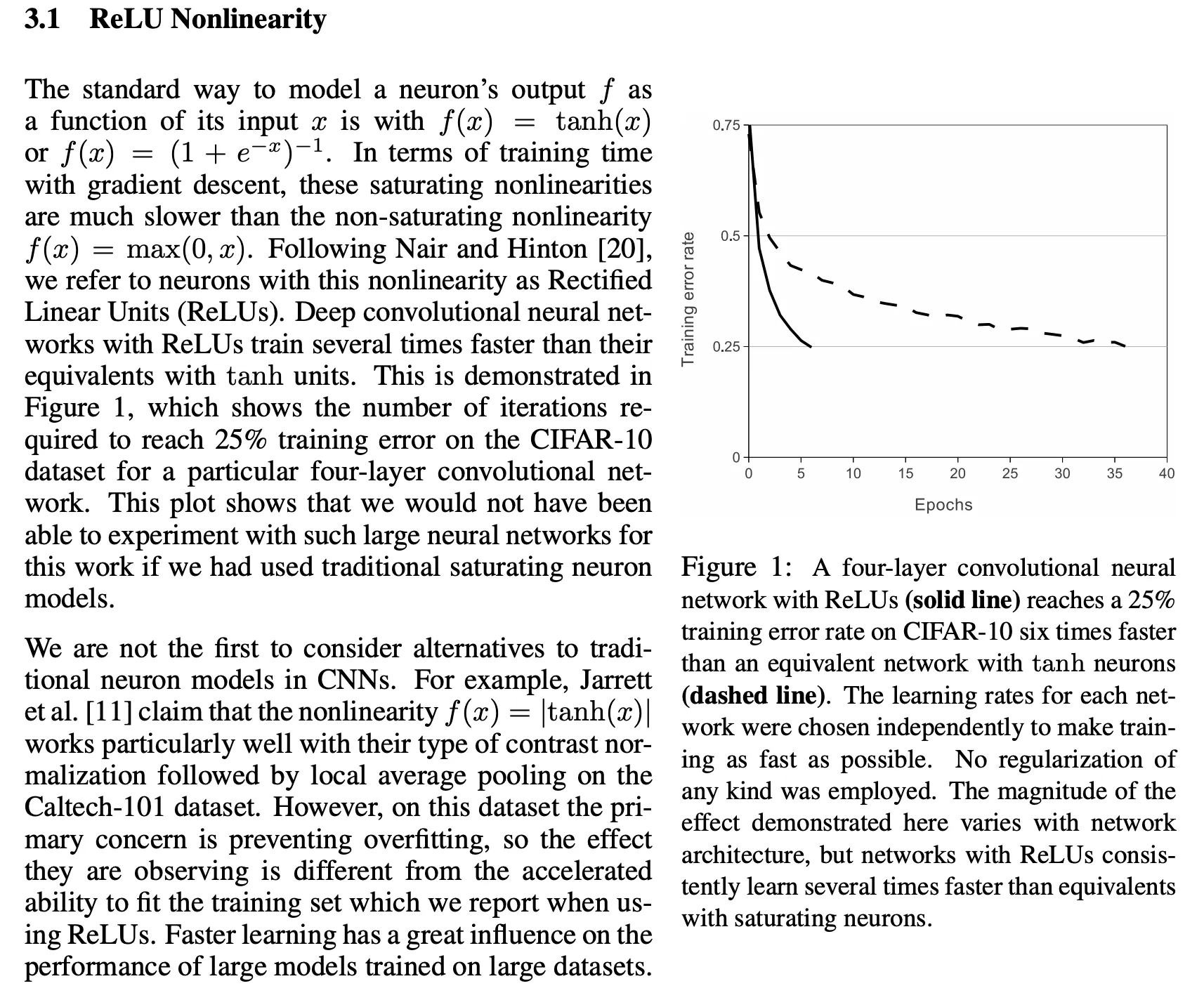
从「传统饱和神经元」到 ReLU,有以下几个好处:
- ReLU 的计算量更小。
- 有效地应对了梯度消失问题(因为 ReLU 在大于零时梯度恒为 1),模型训练时鲁棒性更强。
正则化#
AlexNet 是一个有 60M 参数的大模型,训练数据只有 1.2M 张图片,过拟合是一个非常严重的问题。为了限制过拟合,AlexNet 在模型设计中引入了很多正则化方法。
机器学习里,「正则化」不是某个具体操作,而是一类方法,核心目标是限制模型的过拟合,提高泛化能力。典型做法包括:
- L2(weight decay):通过训练超参数,限制参数大小
- L1:鼓励稀疏
- 数据增强:增加训练分布(稍后介绍 AlexNet 的做法)
- 早停:限制训练时间
- Dropout:随机丢弃神经元
Dropout#
在每一次迭代中,对某全连接层,Dropout通过修改神经网络的结构实现按一定概率将神经元置为0,该神经元不参与前向和反向传播,等同于被删除,此时网络结构不变。

Dropout 的作用:
- 打破 co-adaptation,耦合的、脆弱的表示。
- 等价于模型集成(集成学习),每次 dropout 相当于在训练一个「子网络」。
数据增强#
这句话第二次重复「AlexNet 是一个有 60M 参数的大模型,训练数据只有 1.2M 张图片,过拟合是一个非常严重的问题。」
Dropout 是从模型的参数入手增加鲁棒性,数据增强则是从训练数据入手增加鲁棒性。AlexNet 论文中使用了两种数据增强方法:空间变换和颜色扰动。
空间变换:裁剪、翻转#
训练时,从每张图片中随机裁剪出 的子图(原图是 ),并且随机水平翻转。
种位置,再乘以水平翻转可以得到 2048 倍数据扩增。

测试时,从原图里裁出 5 个 224×224 的 patch,每一张都做一个水平翻转,得到 10 个 patch,分别输入模型进行预测,最后取平均。

可以看作一种提高「平移不变性」的增强方法。
颜色扰动:PCA 光照扰动#
AlexNet 在 RGB 空间做 PCA 分解,沿主成分方向加入随机扰动。
不过它贡献有限(比不上 ReLU / Dropout / GPU),后来也基本没人用,现在被更简单的方法完全替代(color jitter)。
实验实践#
数据增强#
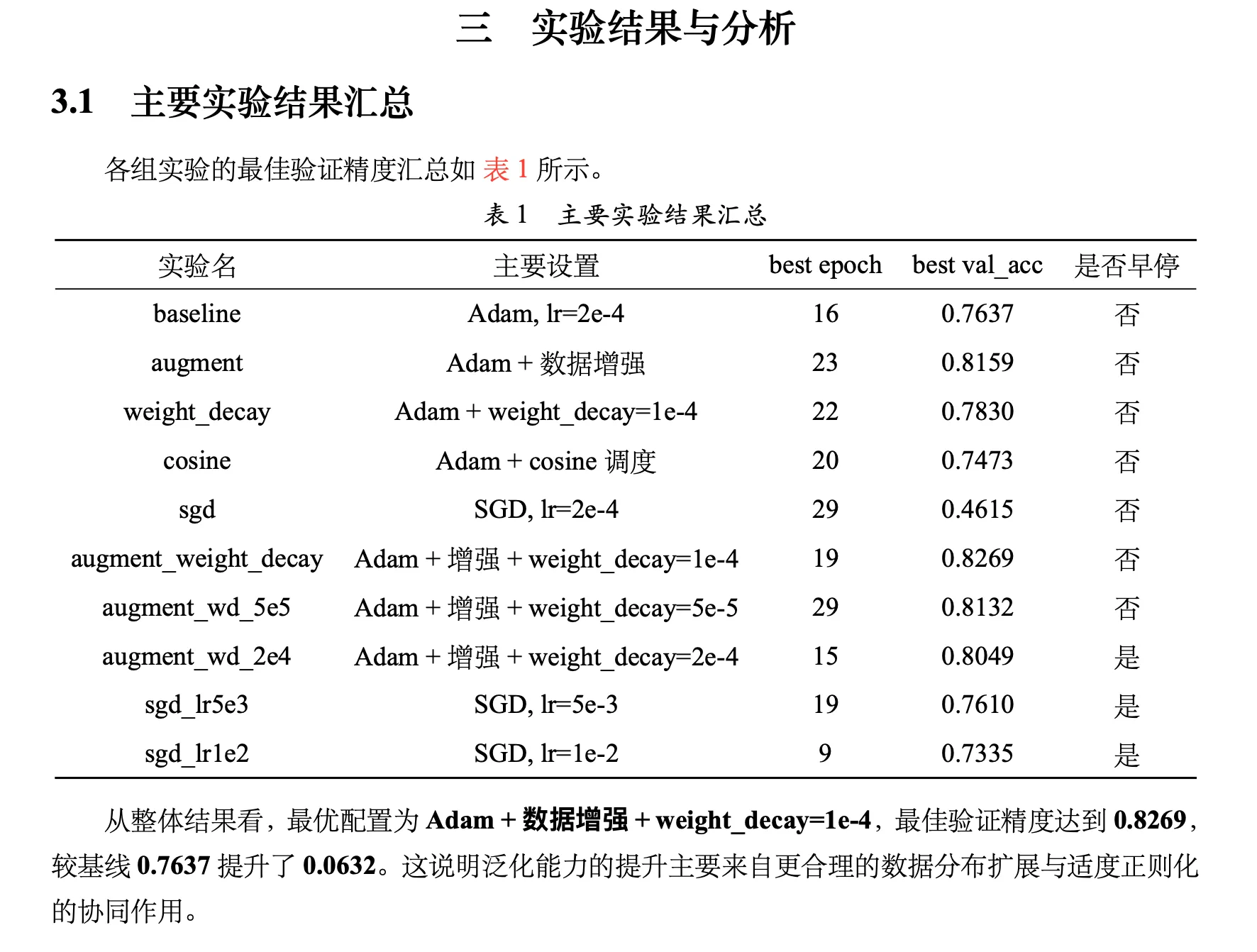
在 AlexNet 为花卉分类的实验中,数据增强的作用非常明显。

仅加入数据增强后,验证精度由 0.7637 提升至 0.8159 (+0.0522)。随机裁剪与水平翻转有效扩展了训练样本分布,缓解了模型对训练集细节的过拟合。同时,最佳 epoch 由第 16 轮推迟至第 23 轮,说明模型需要更多轮次适应多样化输入,但最终获得了更好的泛化效果。数据增强是本实验中收益最显著的单一改进措施。
早停#
在实验过程中,发现大部分模型在第 16-23 轮左右就已经达到了最佳验证精度,继续训练反而会过拟合,验证精度开始下降。因此,早停是一个非常有效的正则化方法,同时它还能减少计算资源的浪费。
权重衰减#
单独加入 weight_decay=1e-4 后,验证精度从 0.7637 提升至 0.7830,表明权重衰减能在一定程度上抑制参数过大、改善泛化,但收益不及数据增强,说明仅靠参数正则化无法替代样本层面的分布扩展。
进一步在”增强 + 权重衰减”组合下对比不同衰减系数:5e-5 对应 0.8132,1e-4 对应0.8269,2e-4 对应 0.8049。
1e-4 在当前实验范围内效果最优——正则化过弱则抑制过拟合不足,过强则限制模型拟合能力。
学习率调度#
加入余弦退火调度后,验证精度反而从 0.7637 降至 0.7473。这说明学习率调度并非在所有场景下都能带来收益。本实验中固定学习率 2e-4 对 Adam 已较为合适,叠加 cosine 调度后后期学习率下降过快,可能导致模型在尚未充分收敛时便进入过小步长阶段。
Adam v.s. SGD#
将 Adam 替换为 SGD 并保持 lr=2e-4 时,最佳验证精度仅为 0.4615。该学习率对 SGD 而言过 小,导致参数更新缓慢、难以充分收敛。补充实验中将学习率提高后:
- :验证精度 0.7610
- :验证精度 0.7335

结果表明,SGD 低性能的主因是学习率不匹配,而非优化器本身的缺陷。但即便调至更合适的 学习率, SGD 在本实验中仍未超过 Adam 系列方案,因此在当前任务规模与训练预算下, Adam 仍为 更稳妥的选择。
这里需要填坑,后续会学习 Adam v.s. SGD 这些优化器的原理和区别,来分析为什么 Adam 在这个实验中表现更好。
Footnotes#
-
ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton ↗ ↩
-
来自原始论文中中的 Figure 2: An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities between the two GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts at the bottom. The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional, and the number of neurons in the network’s remaining layers is given by 253,440–186,624–64,896–64,896–43,264– 4096–4096–1000. ↩
-
定义 和 ,它们的输出分别是 和 ,它们被作者称为「传统饱和神经元」。 ↩
-
Rectified linear units improve restricted boltzmann machines, Vinod Nair, Geoffrey E. Hinton ↗ ↩