吐槽
花了 7 小时写这篇文章,加上之前的时间差不多 20 小时了,但是还是有点懵。回头再看。
问题引入#
假如我们现在有一个 自由度的 RGB 图像空间,现在想在这张画布上生成一只猫的图片,该怎么做?
换成数学语言就是:
在一个 的空间中,找到一个点,使得这个点对应的图像是一只猫。
更进一步:
在一个 维空间里,按照目标分布 的指引进行采样,使得我们采样出来的向量恰好表示一只猫的图像。
这个问题,我们可以形式化为:
我们给定真实数据分布 ,目标是学习一个模型分布 ,使得 能尽可能逼近 ,从中采样出符合要求的图像。
在 VAE 之前,生成式模型主要面临着如下问题:
训练这类模型一直是机器学习领域的一个长期难题,传统上大多数方法都存在以下三个严重缺陷之一:1
- 它们可能需要对数据结构做出强假设。
- 它们可能采用过于粗略的近似,导致模型效果欠佳。
- 它们可能依赖计算成本高昂的推断过程,如马尔可夫链蒙特卡洛方法。
NN 的快速发展让 NN 作为高效的函数逼近器成为可能,VAE 引入变分贝叶斯方法和「最小描述长度」编码模型,为彼时的生成式模型翻开了新的一页。
模型结构#
我们可以从 Pytorch 官方的最小样例中找到一份 VAE 生成手写数字的代码。2
x
│
├── Encoder
│ ├── Linear / Conv
│ ├── ReLU
│ ├── Linear / Conv
│ ├── ReLU
│ └── shared hidden feature h
│
├── From h:
│ ├── Linear -> μ
│ └── Linear -> logvar
│
├── Sample:
│ ├── std = exp(0.5 * logvar)
│ ├── ε ~ N(0, I)
│ └── z = μ + std * ε
│
├── Decoder
│ ├── Linear / Deconv
│ ├── ReLU
│ ├── Linear / Deconv
│ ├── ReLU
│ └── Output layer
│
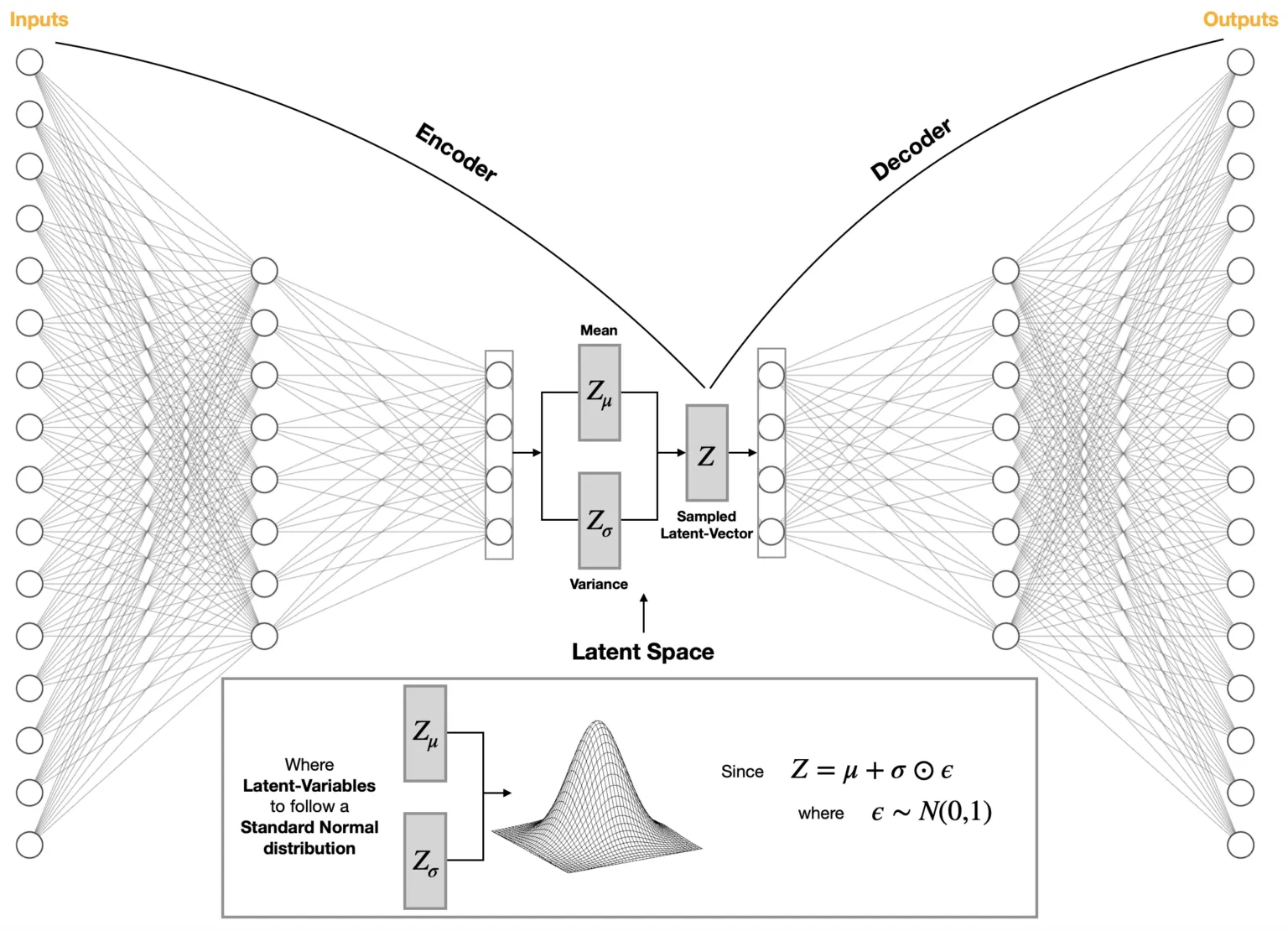
└── x_hat和传统自编码器(AE)对比:
AE 将输入映射为潜空间中的一个点,VAE 将输入映射为潜空间中一个高斯分布的参数( 和 ),通过采样产生隐变量。3

这样,VAE 允许在潜空间采样并生成全新的样本。
Latent Variable Models#
真实世界往往过于复杂,难以直接建模。引入潜变量 之后,我们尝试把复杂的数据分布 分解为:
这里, 是潜空间的先验, 是给定潜变量生成数据的条件分布, 是用于近似后验的推断分布。 在 VAE 中:
- Decoder 实现 ,生成数据
- Encoder 学习近似后验分布 ,辅助训练与推断
简记流程:
其中, 通常取标准正态。
Reparameterization Trick(重参数化)#
「sample」这个步骤是不可微的,所以我们无法通过反向传播来更新 encoder 的参数。
VAE 的解决方案是 reparameterization trick:
每次正向传播时,我们先从一个标准正态分布中采样 ,然后反向传播时,我们可以通过链式法则来计算 和 的梯度。有点像 dropout 的反向传播处理方法。
Loss(Evidence Lower Bound, ELBO)#
我们训练 VAE 的时候,怎么保证两个 FC 学到的就是 和 ?
对于经典 VAE:
x → Encoder → h →
├── fc_mu → μ
└── fc_logvar → logσ²并没有一个明确的结构硬保证。
所以关键不在结构,而在 loss 怎么约束它们。
我们知道, 和 建模的是 ,用来近似真实后验 。
乘以 :
由 Jensen 不等式( 是凹函数,):
拆开:
重建项最大化在 latent 下生成原数据 的概率。重建误差会鼓励 decoder 生成逼近输入的样本。
KL 项保证 latent 空间规整且可采样。它衡量近似后验与先验的距离,防止潜空间过拟合。
这两项共同构成 VAE 的损失函数,约束 和 的学习。